Policy Change Index (PCI)
A Machine Learning Framework to Predict Policy Changes
The Policy Change Index (PCI) is a series of open-source machine learning projects that predict authoritarian regimes’ major policy moves by “reading” their propaganda publications. The first three projects inducted into the series are about China’s policies and based on its official newspaper — the People’s Daily.
PCI-China: predicts China’s policy changes from 1951 Q1 to the present.
PCI-Crackdown: predicts how close in time the 2019-20 Hong Kong protests are to a Tiananmen-like crackdown by China.
PCI-Outbreak: measures the severity of an epidemic outbreak in China, such as COVID-19.
PCI-China and major events in China, 1951 Q1 to 2023 Q4
A spike in the PCI-China signals a major policy change, while a vertical bar marks the ground truth of the change labeled by the event. The PCI-China often spikes months before policy changes take place, validating the index’s predictive power. Click here to learn more about how it works.
PCI-Crackdown for 2019-20 and 2014 Hong Kong protests
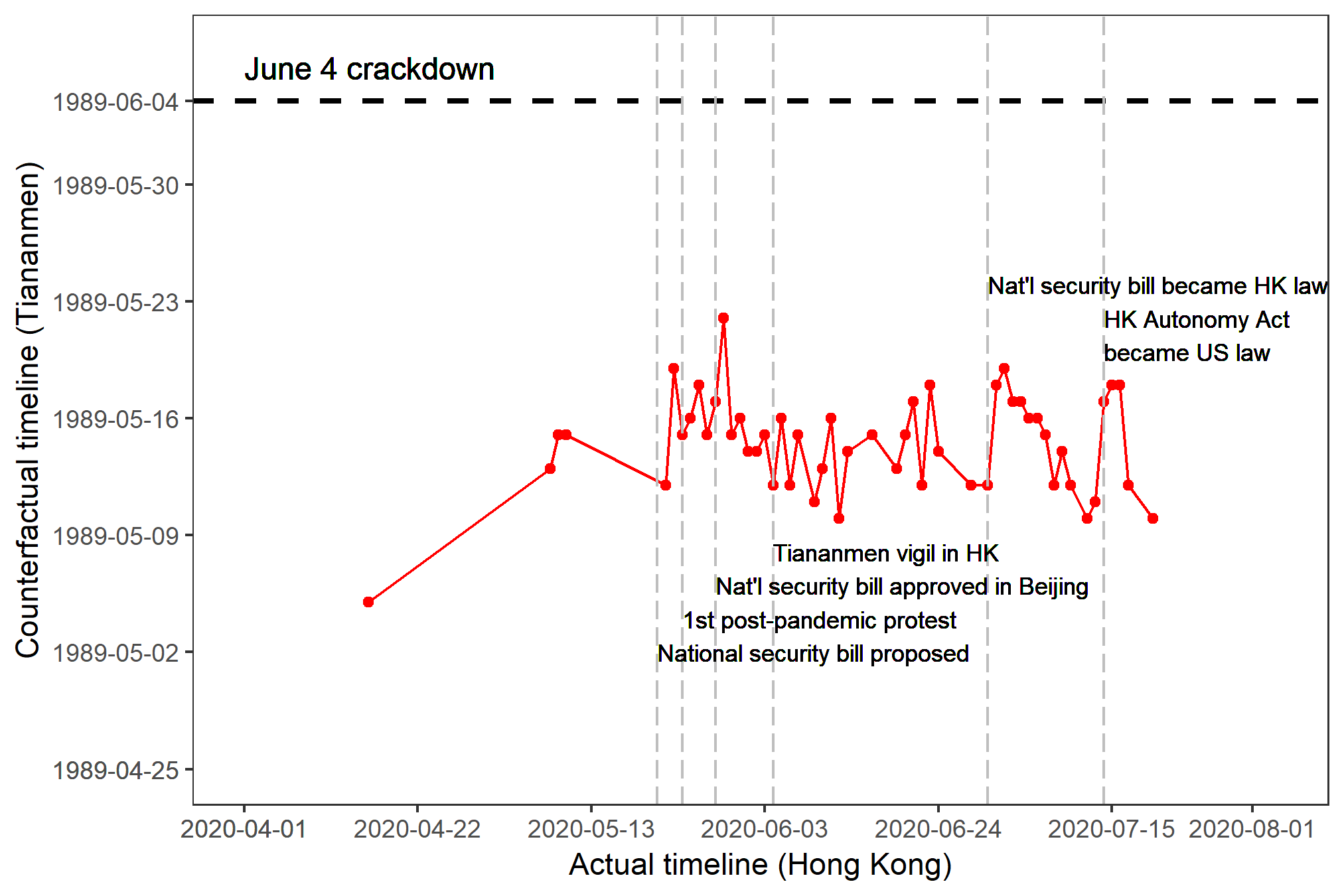
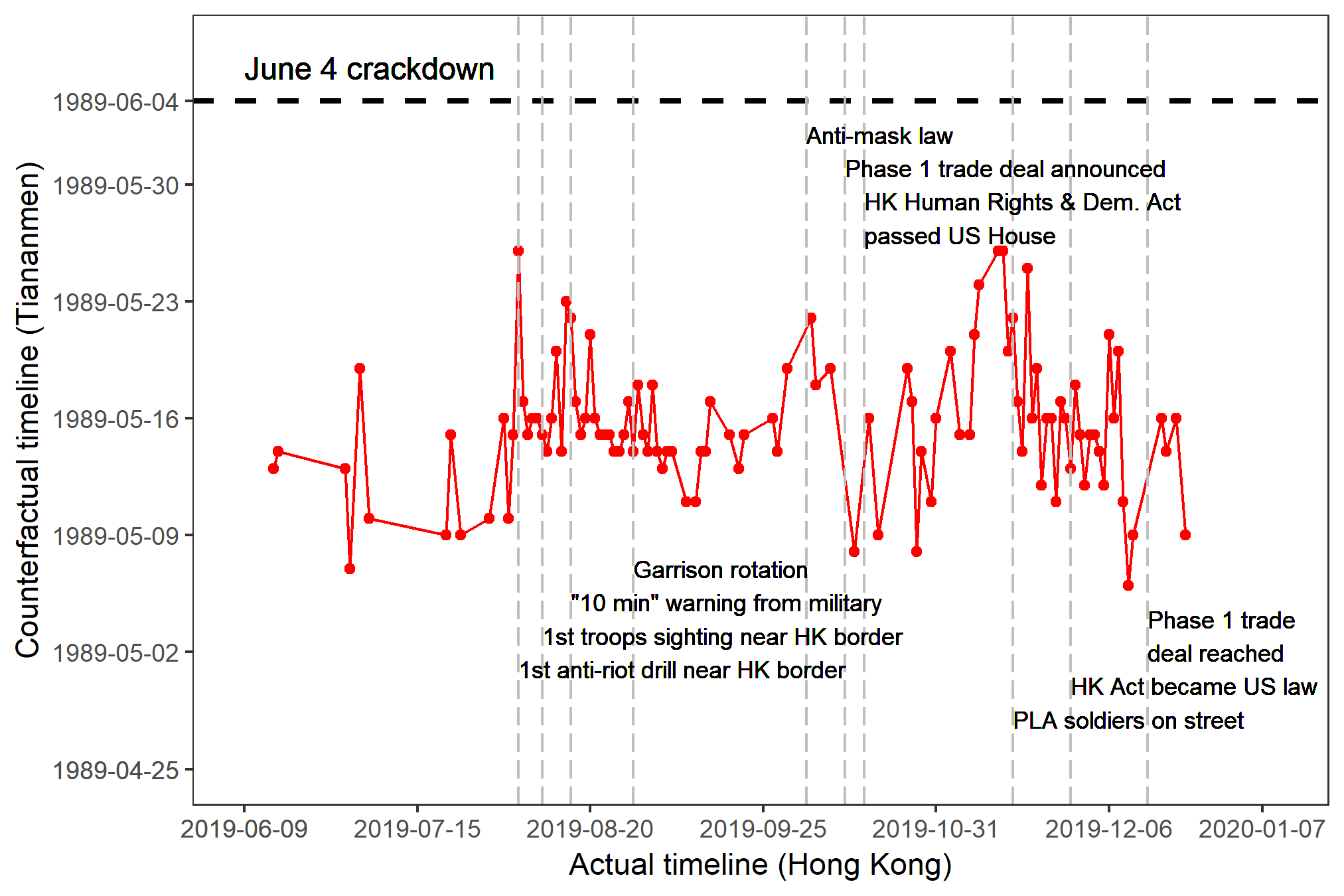
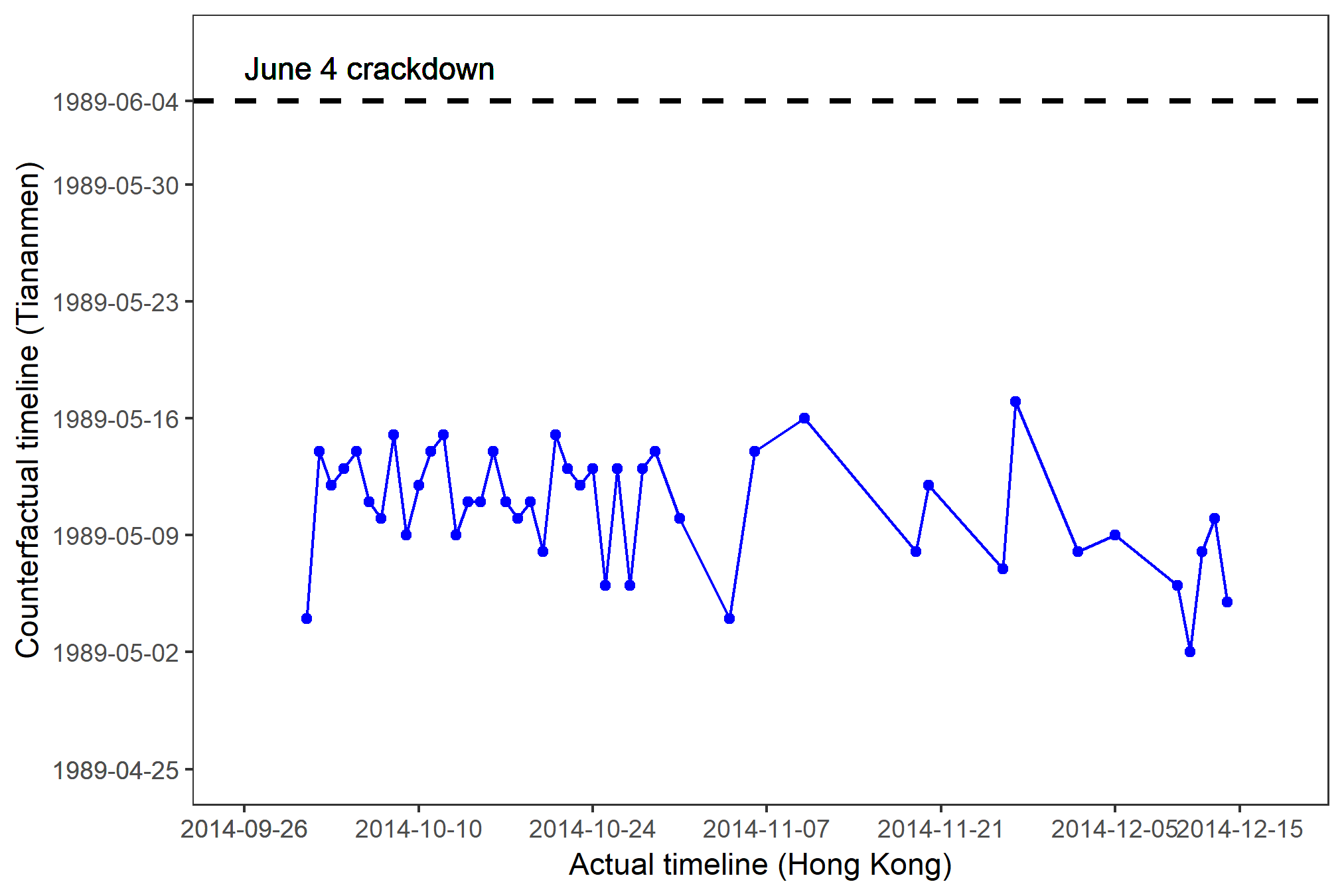
The closer the PCI-Crackdown gets to the June 4 line, the higher the possibility of a Tiananmen-like crackdown. The PCI-Crackdown for the 2019-20 Hong Kong protests remained within three weeks from the crackdown line throughout 2019. The issue reemerged in 2020 as China pushed for a national security law. In comparison, the PCI-Crackdown for the 2014 Hong Kong protests is lower and downward-trending. Click here to learn more about how it works.
2019-20 Hong Kong protests
Second wave: Apr 16 to Jul 20, 2020
First wave: Jun 9, 2019 to Jan 7, 2020
2014 Hong Kong protests, Sep 26 to Dec 15
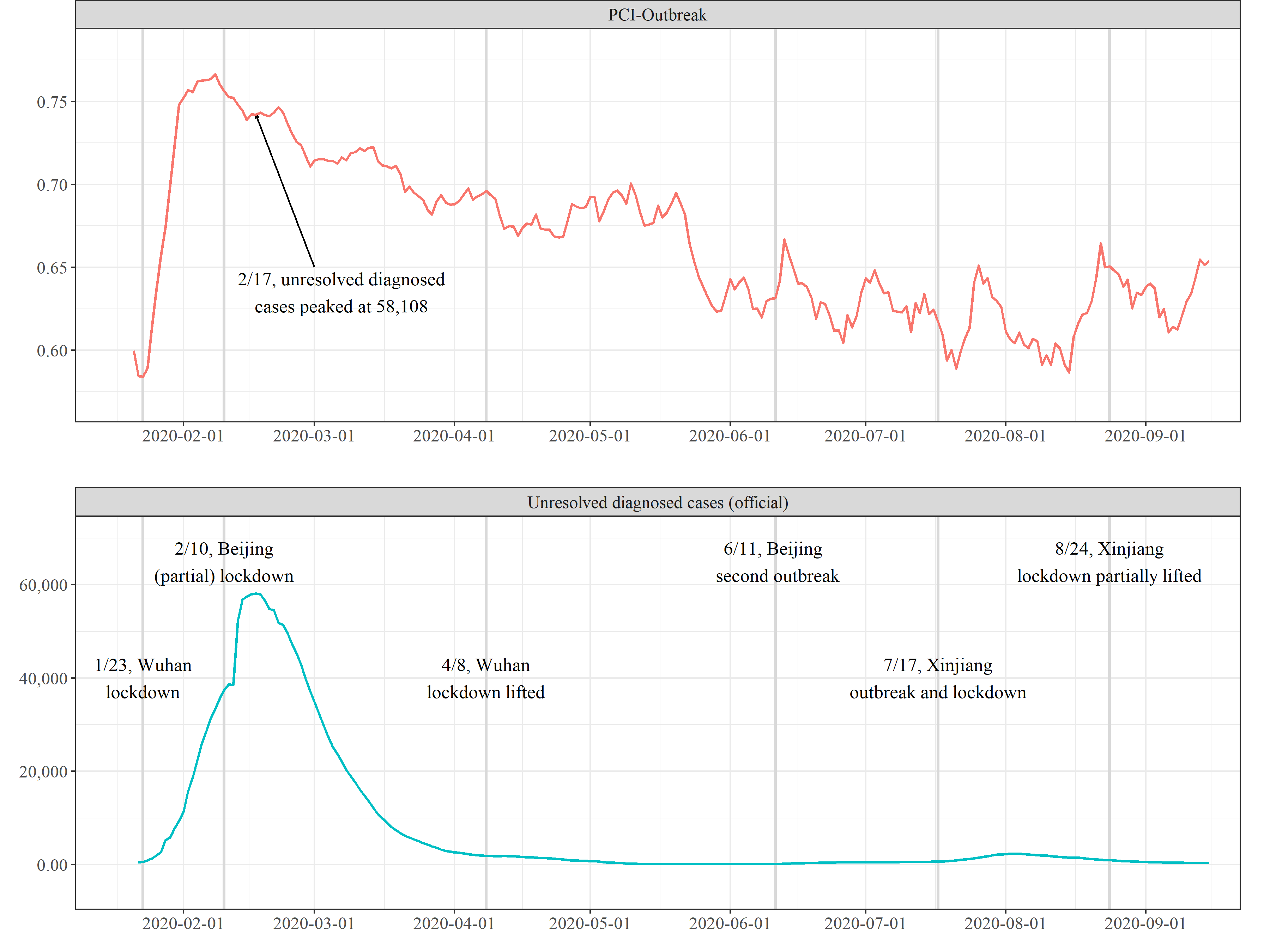
PCI-Outbreak for COVID-19 and official statistics in China (Jan 21 to Sep 15, 2020)
The index uses the 2003 severe acute respiratory syndrome (SARS) as the benchmark. The higher the indicator, the larger the scale of the outbreak. Click here to learn more about how it works.
What’s new
Jan 7, 2024: The 2023 Q4 number of the PCI-China was released.
Nov 15, 2023: The PCI was cited in Axios analyses of the Biden-Xi meeting.
Dec 2022: The PCI’s analyses of China’s Covid policy were cited by the Wall Street Journal and Bloomberg.
Aug 29, 2022: McDaniel and Zhong released an open-source analysis of risks to the U.S. economy if China invades Taiwan.
- May 7, 2022: Zhong told the origin story of the PCI in Washington Examiner.
Feb 10, 2022: Zhong discussed with former House Speaker Newt Gingrich the PCI and the latest China news in the Newt’s World podcast.
Jan 7, 2022: Zhong discussed the PCI and why China’s tighter media control means more opportunities for open-source intelligence.
Sep 13, 2021: McDaniel and Zhong used the PCI-China to assess noneconomic considerations for a U.S.-Taiwan free trade agreement.
Dec 14, 2020: The PCI-Outbreak for COVID-19 in China was updated to September 15, 2020.
Dec 10, 2020: The research paper behind the PCI-Outbreak was released.
- Jul 20, 2020: The PCI-Crackdown for the 2019-20 Hong Kong protests was last updated.
What’s next
PCI-China: to be upgraded to monthly.
PCIs for North Korea, Cuba, Iran, etc.